Data Exploration
Make sure that you've read the Data Collection page first.
Outline
Data Exploration Questions
Preprocessing
Initial Preprocessing
The codes described in this section can be found in preprocessor.py. Thus, all the functions/methods stated in this section can be found on the linked page.
- Handling missing values. (see the method
handle_missing_values)For the columns with string data type, all the empty values are set to the empty string. On the other hand, for the columns with numerical data type, only the 'views' columns have empty values. The empty values of the said column are set to 0.
- Handling outliers. (see the method
handle_outliers)We decided to not remove any of the numerical outliers.
- Ensuring formatting consistency. (see the method
ensure_formatting_consistency)We ensured formatting consistency for all the manually-labeled columns, which are: leni_sentiment, marcos_sentiment, incident, account_type, tweet_type, content_type, keywords, and alt-text. After lower-casing all the above columns, we used regex pattern matching to verify that all the following criteria are met:
- leni_sentiment - values should be one of the following only: "negative", "neutral", "positive".
- marcos_sentiment - values should be one of the following only: "negative", "neutral", "positive".
- account_type - values should be one of the following only: "identified", "anonymous", "media".
- tweet_type - values should be a combination of the following values only: "text", "image", "video", "url", "reply".
- country - values should be one of the following values only: "unspecified", "" (empty string), any alphabetic string.
- content_type - values should be a combination of the following values only: "rational", "emotional", "transactional".
- keywords - any alphanumeric string that is not empty.
- alt-text - values should be one of the following values only: any string enclosed by curly braces { }, "" (empty string)
Note that there is no need to ensure formatting consistency for the date columns. This is because the scraper already provided us with date values so it is guaranteed that the date values are correct and properly formatted. - Normalization and standardization. (see the method
norm_std_ize)For context, here are all the numerical features/columns:
*Note: we converted the date columns (thefollowing followers likes replies retweets quote_tweets views has_leni_ref joined_unix* date_posted_unix* joinedanddate_postedcolumns) to numerical values by converting them to unix time, so we can perform normalization and standardization to their values as well.
We normalized each numerical column (all the features in the table above) by translating and scaling their values to the range [0, 1]. We also standardized each numerical column by getting their z-scores. This whole process resulted to two new columns for each numerical column. - Categorical data encoding. (see the method
encode_cat_feats)For context, here are all the categorical data columns.
There are two types of categorical data columns. First are those columns that can only have a single category (these are leni_sentiment, marcos_sentiment, incident, account_type, and country). Second are those columns that can have multiple categories (tweet_type and content_type). You may refer again to the Ensuring formatting consistency bullet above for the valid values of these columns.leni_sentiment marcos_sentiment incident account_type country tweet_type content_type
We'll discuss first the single category columns. We converted each single category columns to numerical data by following the mapping below.- leni_sentiment: (negative, neutral, positive) → (-1, 0, 1)
- marcos_sentiment: (negative, neutral, positive) → (-1, 0, 1)
- incident: (baguio, ladder, scandal, quarantine, others) → (0, 1, 2, 3, 4)
- account_type: (anonymous, identified, media) → (0, 1, 2)
- country: ("" or unspecified, any alphabetic string) → (0, 1)
As you may have observed, the tweet_type_code is obtained by getting the first letter of each category, sorting all of the first-letter-characters, and concatenating them to form a string (the tweet_type_code). The same process is done for the content_type_code.tweet_type tweet_type_code content_type content_type_code text T emotional E text, image, url ITU rational, emotional ER text, url, image, reply IRTU emotional, transactional ET reply, video, text, url, image IRTUV transactional, rational, emotional ERT text, url, image, reply, video IRTUV rational, emotional, transactional ERT
The possible values of tweet_type_code is essentially all the possible combinations of the set {'I', 'R', 'T', 'U', 'V'} sorted lexicographically, which is 32 combinations in total (thus, 32 possible tweet_type_codes). What this means is that we can map each 32 codes/combinations to integers from 0 to 31. This mapping is then used to convert a tweet_type_code to its corresponding numerical value.
The same process goes for the content_type_code (where the content_type_codes are essentially all the possible combinations of the set {'E', 'R', 'T'}).
Natural Language Processing
The codes described in this section can be found in nlp.py. Thus, all the functions/methods stated in this section can be found on the linked page.
- Tokenization and lower casing.
- Stop words removal.
- Stemming and lemmatization.
The team wrote a code inspired by the natural language processing notebook provided by the professor. First, emojis and punctuation were replaced with their word counterparts. It can be noted that a number of emojis and punctuations have persisted. To address this, all the unaffected punctuation and emojis were manually translated. The resulting text was casted into lowercase.
Next, the team installed the googletrans api version 3.1.0a0. This was the method used in translating the Tagalog tweets into English. The team does not have a focus on NLP anyway. However, there were empty tweets because such tweets were only images. The error was finally caught and empty tweets translated into empty strings.
Lastly, the tweets were tokenized using the nltk. The rest of the professor's code has worked nicely. In the end, the disinformation dataframe was appended the stemmed and lemmatized versions of the tweets. It should be noted that the tweets were translated poorly by the automatic translator.
But, actually, the group has performed some kind of natural language processing manually. The team has identified the aliases being mentioned in the disinformation tweets. More about this will be discuss at the latter part of this article below.
Time Series Processing
The codes described in this section can be found in time_series.py. Thus, all the functions/methods stated in this section can be found on the linked page.
- Interpolation
All our samples have no missing datetime values. Thus, there is no need to interpolate any datetime values.
- Binning (see the method
bin)The two datetime columns (joined and date_posted) are binned daily, weekly, monthly, and yearly. Thus, this results in eight new columns, which are:
Below are some of the values of each bin:joined_day joined_week joined_month joined_year date_posted_day date_posted_week date_posted_month date_posted_year - For yearly bins: 2016, 2017, ... (yyyy)
- For monthly bins: 2016-1, 2016-2, ... (yyyy-mm)
- For weekly bins: 2016-1, 2016-2, ... (yyyy-ww)
- For daily bins: 2016-1-1, 2016-1-2, ... (yyyy-mm-dd)
Feature Analysis
- Feature selection (see the method
feature_selection)Features with zero variance are removed. We used
scikit-learn'sVarianceThresholdto perform this. Three columns were removed, which areviews,views_std(standardized views), andviews_norm(normalized views). This is because all the values of the views column are actually empty (and thus were set to 0 in the preprocessing stage.) - Dimensionality reduction
We were not able to implement this.
- Feature engineering (see the method
feature_engineering)The following new features were generated.
- followers_bin. This is the binned version of the
followerscolumn. The bins are (-inf, 10], (10, 100], (100, 1000], (1000, 10000], (10000, inf), which are labeled as 0, 1, 2, 3, 4, respectively. - engagement. Based on the equation:
engagement = likes + replies + retweets + quote_tweets. - engagement_bin. This is the binned version of the
engagementcolumn. The bins are (-inf, 10], (10, 100], (100, 1000], (1000, 10000], (10000, inf), which are labeled as 0, 1, 2, 3, 4, respectively. - diff_joined_election. Based on the equation:
diff_joined_election = joined - election_date(in terms of days), whereelection_dateis May 9, 2022. - diff_date_posted_election. Likewise,
diff_date_posted_election = date_posted - election_date(in terms of days), whereelection_dateis May 9, 2022.
- followers_bin. This is the binned version of the
Visualization
In this section, the results of data exploration are presented through different graphs. All the plot creation logic can be found in visualizer.py.
Distribution of Tweets by Disinformation Incident
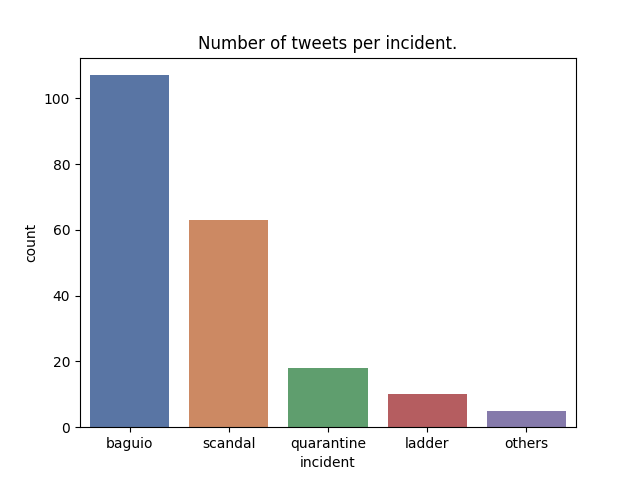
It is important to note that it has been several months after the 2022 elections. Therefore, the collected data is prone to survivorship bias. Due to the fact-checking community, it is reasonable to think that disinformation tweets have already been deleted.
The data collection methodology should also be put into consideration. The team looked up fact-checking articles involving the Robredo sisters and created the tweet keywords from the articles. This implies that the bar graph above, the distribution of tweets across disinformation incidents, may not reflect the actual extent of the allegations.
Distribution of Tweets Targeting a Specific Robredo
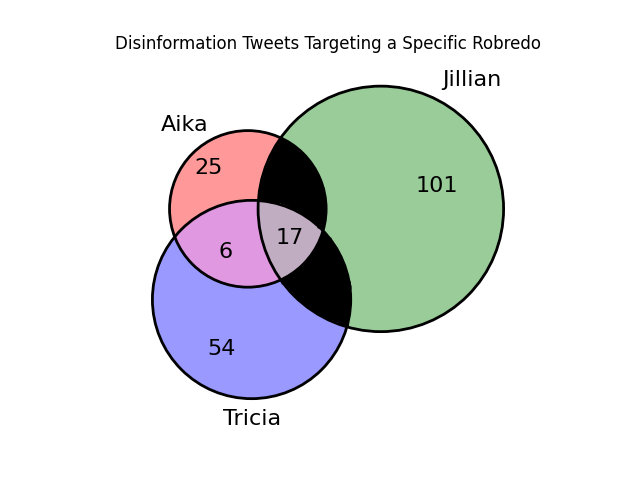
It is interesting to note that Jillian Robredo is the Robredo sister that is mentioned most among the tweets. This is because the Baguio incident is the incident with the highest number of mentions, as seen in the "Number of tweets per incident" barchart.
Distribution of Incident Tweets per Day
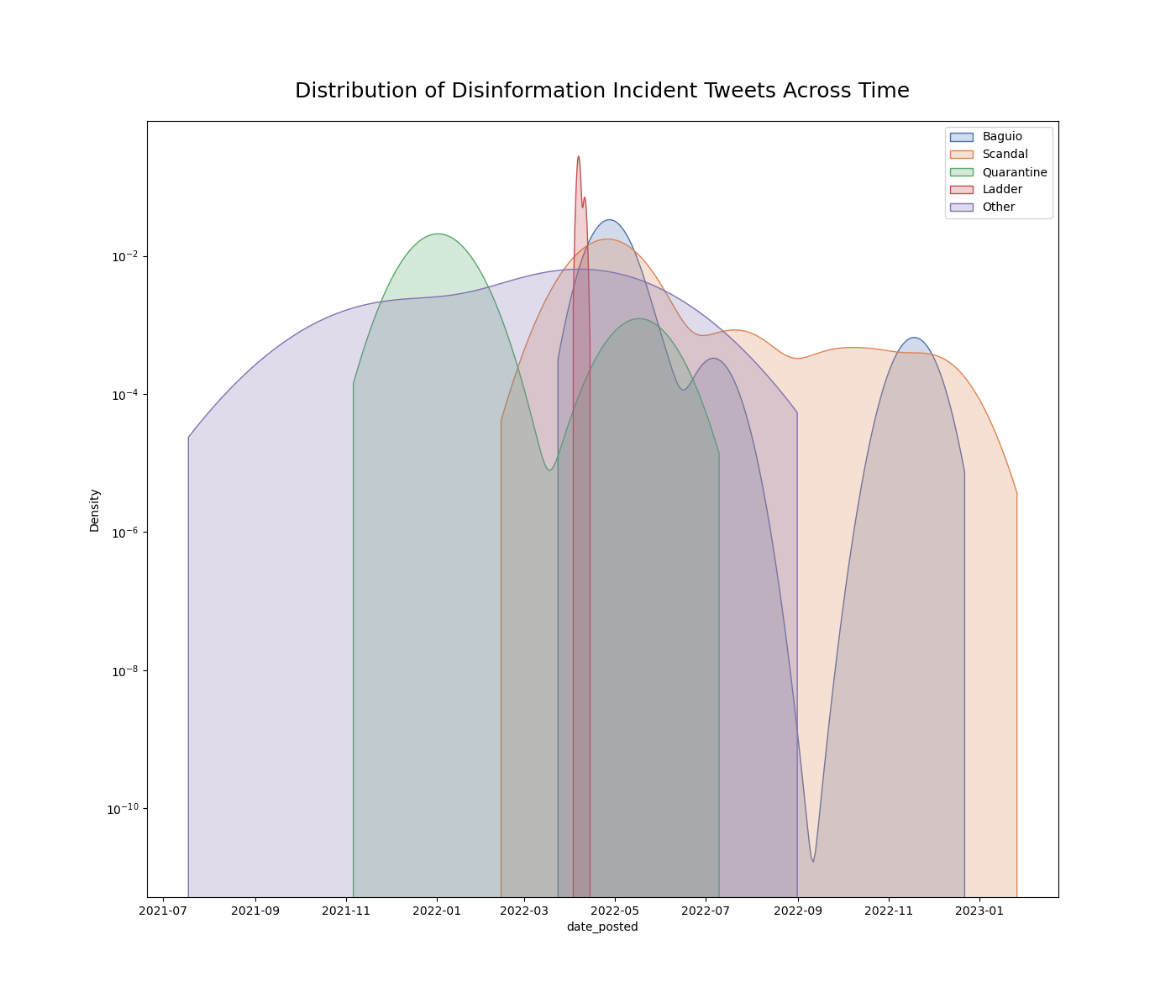
It is also interesting to graph and observe when each incident was the most popular. Interestingly, the highest peak of each disinformation incident is a hundredfold taller than the other peaks. This means that the tweets were categorized nicely. The presence of the other peaks also means that after the onset of a disinformation incident, twitter users tend to talk about it again at a later time. Kindly refer to the Data Collection page for more information about the items in the graph legend.
Suspect Events leading to Disinformation Incident
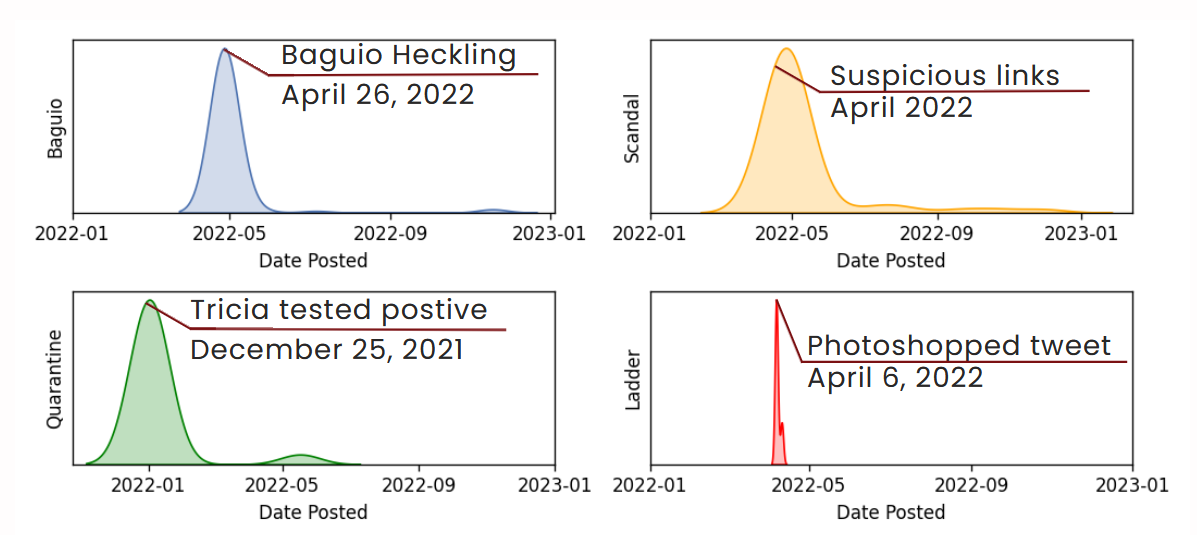
The Baguio incident disinformation tweets were possibly triggered by the heckling at the Baguio Public Market on April 26, 2022. The Scandal incident disinformation tweets were possibly triggered by the surfacing of suspicious links on April 11, 2022. The Quarantine incident disinformation tweets were possibly triggered by Jay Sonza's Facebook post on December 25, 2021. The Ladder incident disinformation tweets were possibly triggered by Jam Magno's tweet on April 6, 2022.
Cumulative Count of Disinformation Tweets
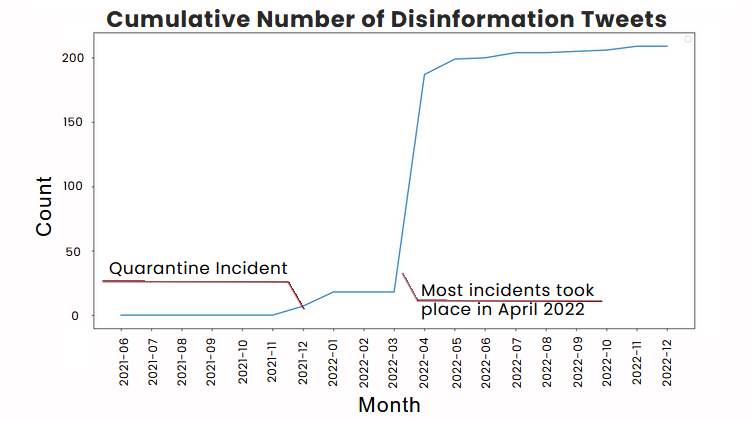
Our group find it interesting that the highest increase in disinformation tweets occured just a month before the election. Moreover, as we'll see in the next section, a number of disinformation tweets have negative tweets towards ex-VP Leni Robredo. Our opinion from these observations is that the Robredo siblings were used by trolls and fake news peddlers to ruin the image of the ex-VP in order to reduce her chances of winning the national elections.
Distribution of Tweets Across Leni, Marcos Sentiment
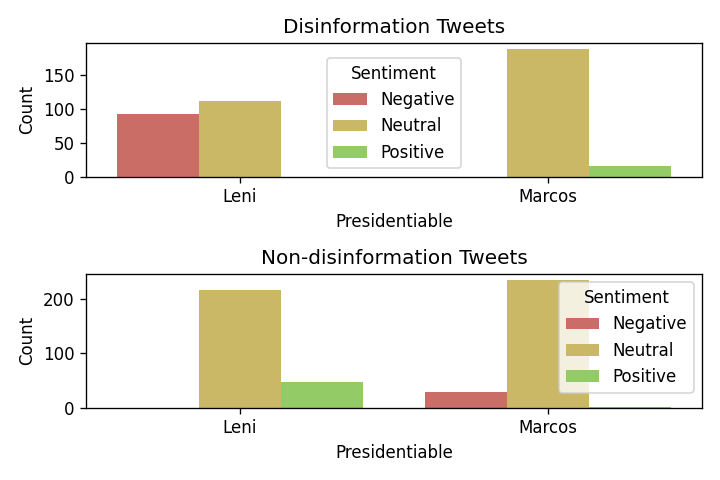
The tweets, both disinformation and non-disinformation, may also be grouped according to their sentiment towards the presidentiables last 2022 elections. Interestingly, there are no positive sentiments for Leni Robredo and no negative sentiments against Bongbong Marcos among disinformation tweets. This is reminiscent of a news during the campaign period. Tsek.ph: 92% of false info favorable to Marcos, 96% of disinformation vs Robredo negative. On the other hand, there are no negative sentiments for Leni Robredo and no positive sentiments against Bongbong Marcos among non-disinformation tweets.
Names Entangled in the Mire of Disinformation
There are certain names referring to certain individuals appearing in the disinformation tweets.
Names in the Baguio Incident
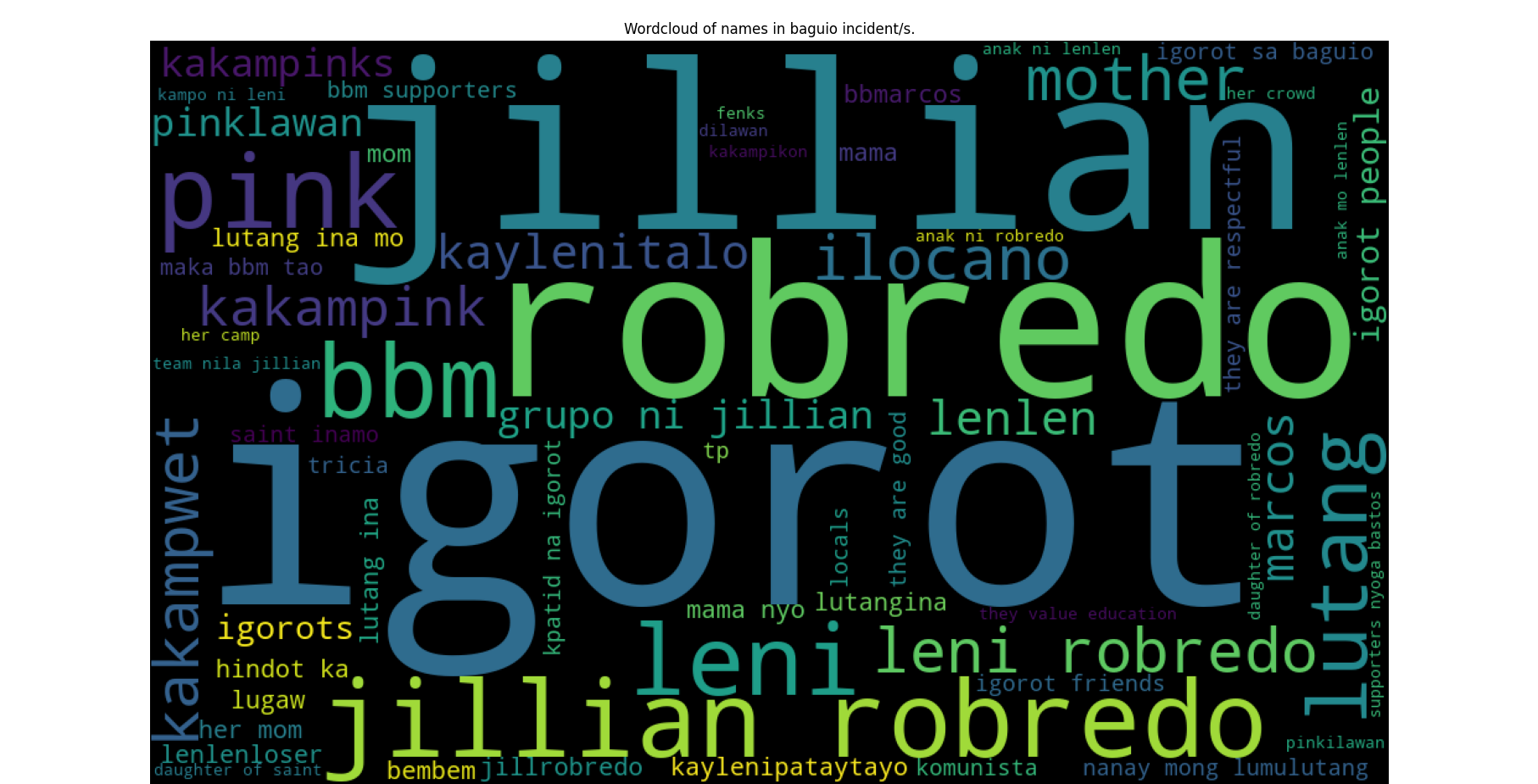
Names in the Scandal Incident

Names in the Quaratine Incident

Names in the Ladder Incident

Names in Other Incidents

The largest aliases appearing in the word clouds are the victims of the corresponding disinformation incident, which is the Robredo family. Naturally, the key words appearing are dependent on the situation and nature of the incidents. In the Baguio incident, most tweets are talking about the Kakampinks by calling them names such as "kakampwet", "pinklawan", and "kakampikon." In the Ladder incident, there were fewer names because Jam Magno's tweet is not easily believable and that the incident was short-lived.
Now, it is interesting to observe the medium-size aliases. No disinformation incident fell short in mentioning Leni Robredo and her aliases such as "lutang" and "lugaw." This is a confirmation of the real world observation of the team, that Leni Robredo was being implicated in most disinformation incident which is most notable in the Quarantine incident.
The word clouds were accomplished by tokenizing all the tweets and manually identifying the entity associated with each token. We have collected more than 9000 1-gram, 2-gram, and 3-gram tokens and labeled about a hundred as referring to relevant individuals and groups of people. In the case of ambiguous terms, we referred back to the original tweets to identify the entity the tweets were referring to. In total, we named 14 relevant entities. The code for vectorization and counting references can be found in misc_computations.py
FUN FACT: Jillian's Baguio group was associated with Karens of the English speaking world.
| Entity | Aliases | Number of References* |
|---|---|---|
| Individuals | ||
| Aika Robredo | "aika", "aika diri", "aika robredo", "aika rob", "she admitted" | 34 |
| Bam Aquino | "bembem" | 1** |
| Bongbong Marcos | "bbm", "bbmarcos", "marcos" | 24 |
| Gwyneth Chua | "chua" | 2 |
| Jillian Robredo | "jillian robredo", "mrs robredo daughter", "hindot ka", "jillian", "jillrobredo", "ma am jill" | 60 |
| Leni Robredo | "kaylenipataytayo", "kaylenitalo", "leni lugaw", "leni robredog", "lutangina", "mrs robredo", "president leni", "president leni robredo", "vp leni", "vice president", "withdrawleni", "fake vp", "fake vp leni", "her mom", "lenlen" "lenlenloser", "leni", "leni robredo", "lenirobredo", "lugaw", "lutang", "lutang ina", "lutang ina mo", "mama", "mama nyo", "mom", "mother", "nanay kong lutang", "nanay mong lumulutang", "philippines vice president", "robredog", "saint inamo", "sarili niyang ina" | 125 |
| Tricia Robredo | "tricia", "tricia robredo", "trisha", "trisha robredo", "vice president daughter", "she went straight" | 120 |
| Thinking Pinoy | "tp" | 1 |
| Groups | ||
| BBM Supporters | "bbm supporters", "maka bbm tao" | 4 |
| Communists | "cpp", "cpp ndf npa", "komunista" | 3 |
| Filipino People | "igorot sa baguio", "igorots", "igorot people", "igorot", "igorot friends", "igorot native", "ilocano", "kpatid na igorot", "locals", "taong bayan", "they are good", "they are respectful", "they value education" | 85 |
| Jillian's Baguio Group | "grupo ni jillian", "her camp", "her crowd", "team nila jillian" | 6 |
| Kakampinks | "baguio fenks", "dilapinks", "dilawkadiri", "dilawan", "fenks", "kakampikon", "kakampwet", "kakamdogs", "kakampink", "kakampinks", "kampo ni leni", "pink", "pinkilawan", "pinklawan", "supporters nyoga bastos" | 25 |
| Robredo Family | "anak ni leni", "anak mo lenlen", "anak ni lenlen", "anak ni robredo", "daughter of robredo", "daughter of saint", "daughter of lugaw", "mga robredo", "mga anak niya", "robredo", "tatlong anak" | 118 |
*The number of references to an entity is simply the sum of all the appearances of each gram in the tweets.
**Due to being a single reference to Bam Aquino, "bembem A." and its associated tweet does not conclusively refer to Bam Aquino. However, there is a circulating cartoon of Leni and Bam Aquino in which they supposedly planned the scandal issue.
Note: The team has accomplished stemming and lemmatization of the tweets. However, this method was discontinued due to poor translation of Google Translate and time considerations. Moreover, translating the tweets in English would lose some valuable data from the tweets. For instance, the invented aliases for Leni "lugaw" and "lutang" gave rise to adjective and verb derivatives. It is not preferable to translate "lugaw" as porridge and "lumulutang-lutang" as floating.
FEATURING:
The Disinfo Account
This card attempts to describe the “average” features of an account involved in posting disinformation.
| Account type | Anonymous* |
| Most Disinfo Tweets from a Single Account | 6 |
| Location | Unspecified** |
| Median Following | 216 |
| Median Followers | 212 |
*Accounts are tagged anonymous when the accounts have pseudonyms, aliases, or names/bio which are untraceable. Accounts are tagged as identified when the accounts have real names, bio and/or which are verified. Accounts are tagged as media when the accounts are owned by news outlets/personalities or are pretending to be.
**Location is tagged as unspecified when the twitter user shared a location that cannot be identified with any country, or shared an obscure location. The team labeled locations with countries when applicable. Twitter accounts who have not shared their location were ignored.
Distribution of Accounts That Joined Twitter per Month
Cumulative Distribution of Accounts That Joined Twitter per Month
These line graphs were made using plotly. In the upper graph, it can be seen that the highest number of accounts joined is in April 2022. In the lower graph, the cumulative version is shown. There were a total of 158 disinformation accounts collected in this project.
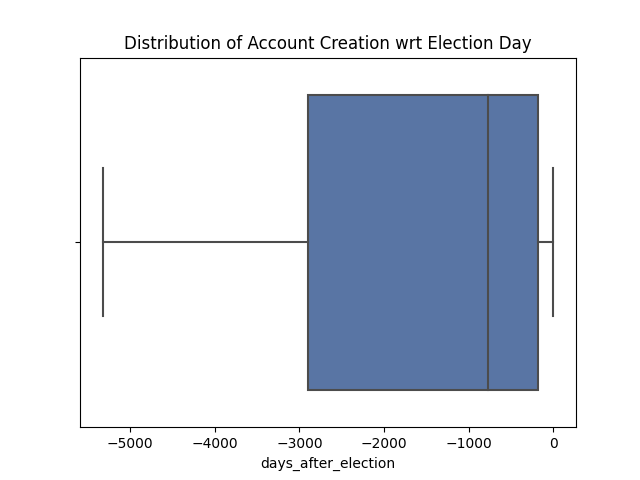
All account creation dates were compared to the election date resulting in the number of months an account has joined after the election (the values are negative). This means that May 2022 is the “zero” of the x-axis and an account joining twitter in December 2021 will be assigned the value -5. The data is skewed to the right. All accounts have joined before the elections.
FEATURING:
The Disinfo Tweet
This card attempts to describe the “average” features of an account involved in posting disinformation.
| Person with the Most References | Leni Robredo* |
| Tweets with Negative Sentiments to Leni Robredo | 25% of Disinfo Tweets |
| Tweets with Negative Sentiments to Bongbong Marcos | 8% of Disinfo Tweets |
| Median Tweet Length | 22 words |
| Median Tweet Engagement | 1 |
| Most Common Content Type | Rational |
*Person with the most references other than Aika, Tricia, or Jillian Robredo.
**Engagement is the sum of likes, replies, retweets, and quotes of a tweet.
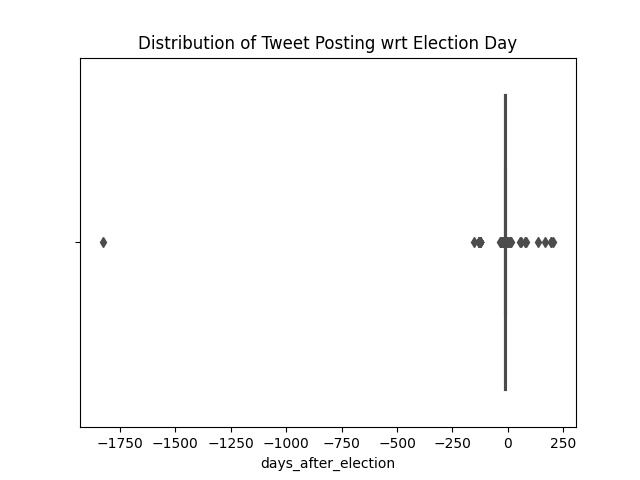
Similar to the account creation dates, the day of the election takes the “zero” value of the x-axis. The tweets are assigned the number of days they are posted after the election (most values are negative.) There is one outlier, a tweet posted in 2017 which was included because there are few data. The data is skewed to the right. Interestingly, some tweets were posted way past the election day.
Distribution of Tweets With Negative Leni-Sentiment per Day
This line graph was made using plotly. It is interesting to note that the highest number of posted tweets with negative Leni sentiment occurred on the 27th of April 2022, also before the 2022 Elections. Moreover, most of the tweets that are labeled 'Negative' in the leni_sentiment column were generated in 2022.
Wordcloud of a Tweet

This word cloud shows the aliases being mentioned in all the disinformation tweets collected by the team. No surprise when the largest word is Robredo and the first names of the women. Although it is reasonable to expect the name "leni," the appearances of the invented caricature names for the former vice president is harrassment in our opinion.
Feature Trends
Leni Sentiment Pairplot
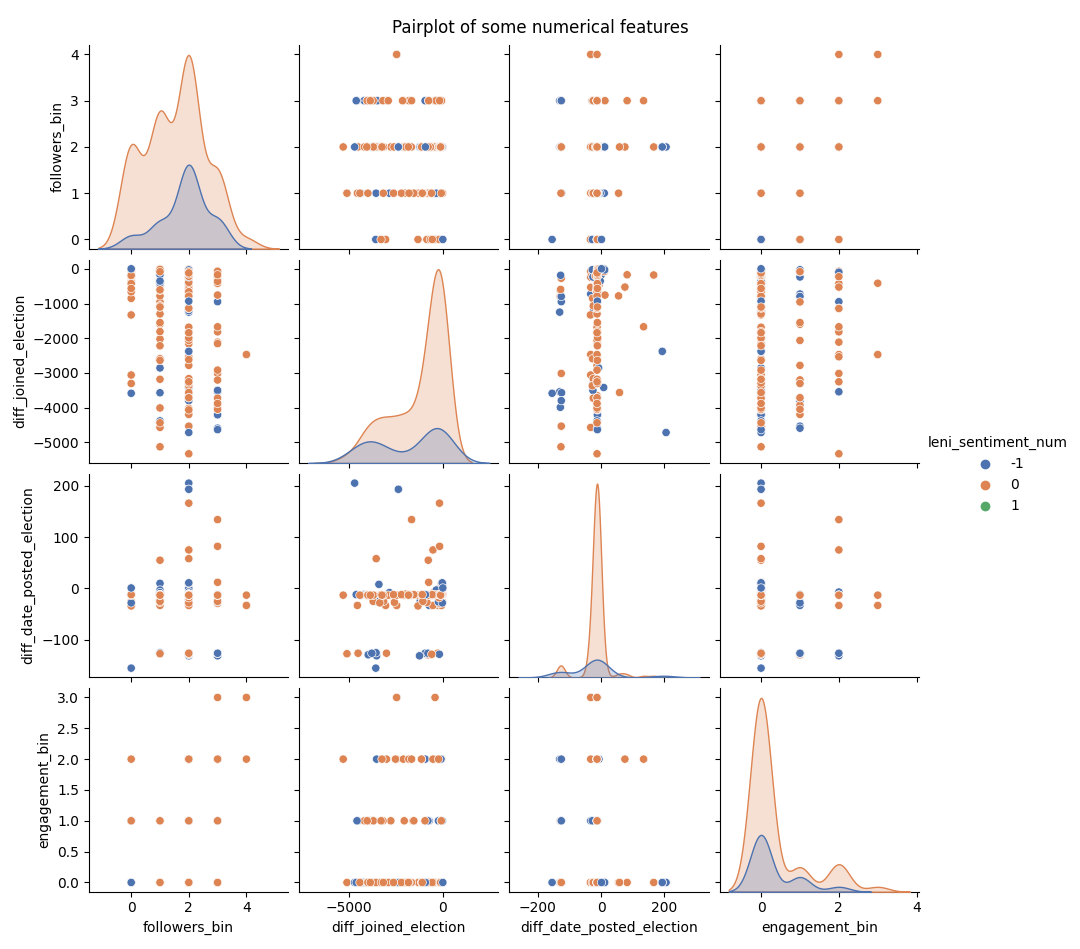
In most cases, the distribution of the data points do not imply some relationship about the variable Leni Sentiment. There is one pair that is noticeably correlated, the pair of followers and engagement. It is predictable that these two variables are correlated.
In this pairplot, the single outlier of diff_date_posted_election was ignored because it obscured the visualization of the graph.
Leni Reference Pairplot
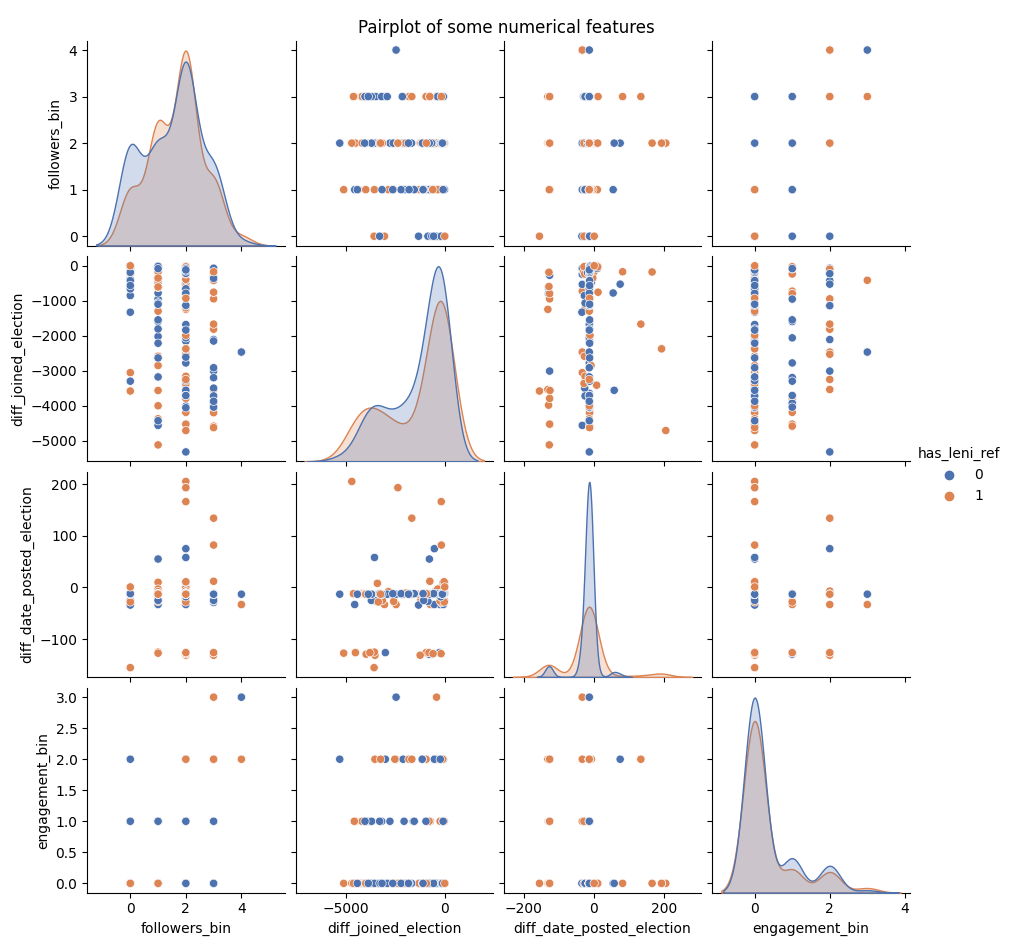
Similar to the pairplot above, this graph also does not show significant relationship between the variable has_leni_ref and the select features.
Features Heatmap
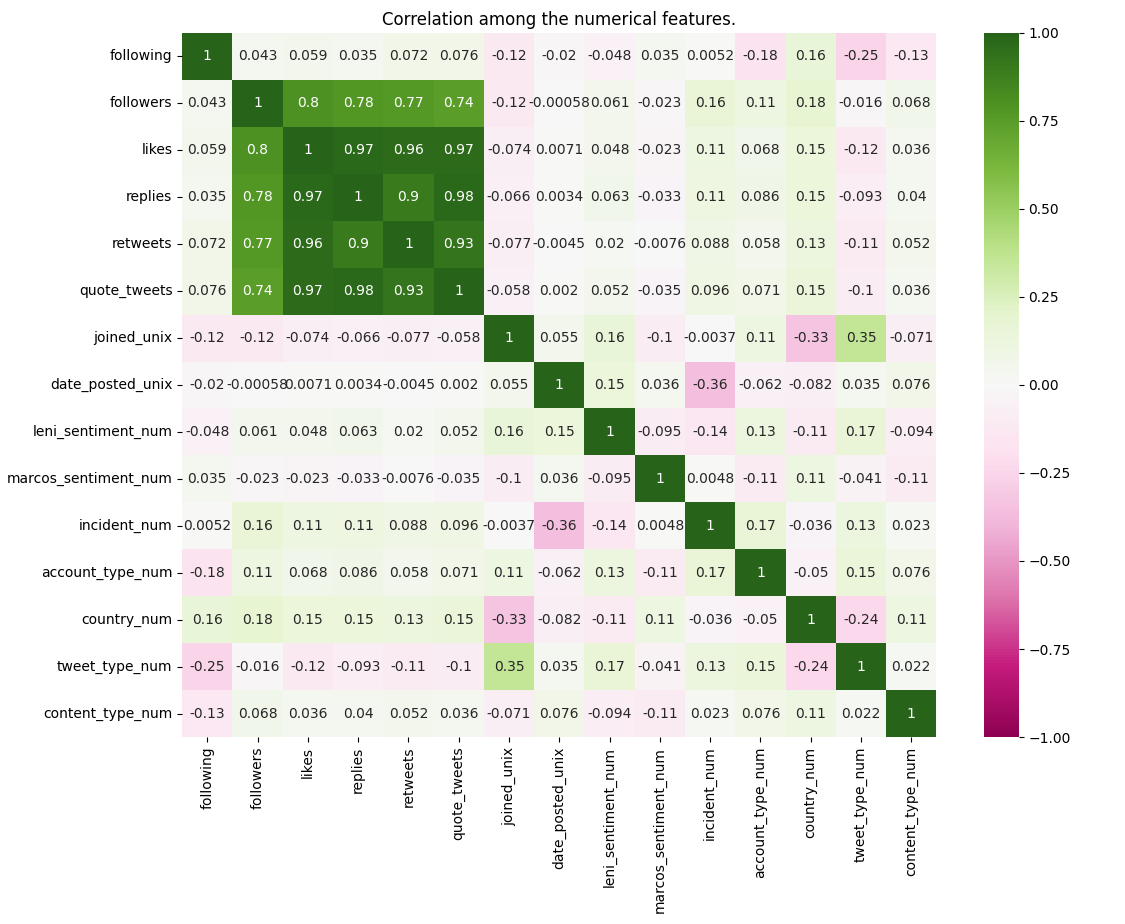
Most features have negligible correlation. Variables related engagement and popularity of an account are significantly correlated. This is to be expected in social media environments. According to Laerd Statistics, the following are the thresholds for the interpretation of the absolute value of correlation r:
- .1 to .3 means "small" correlation
- .3 to .5 means "medium" correlation
- .5 to 1 means "large" correlation
Following and followers have a large correlation. Based on the social media experience of the team, Filipinos mostly have a "follow me I'll follow you back" culture. Some of the "medium" correlations involved categorical variables which means the correlation has no meaning.
Of significance are the variables Leni Sentiment and Marcos Sentiment, which refer to the sentiment of a tweet to Leni Robredo and Bongbong Marcos respectively. Unfortunately, the heatmap enables the team to not conclusively draw relations of other features to these variables.